Druid 소개
OLAP을 위해 설계된 실시간 데이터 분석용 데이터베이스.
- 클릭스트림 분석
- 네트워크 성능 모니터링을 포함한 네트워크 분석
- 서버 메트릭 저장소
- 애플리케이션 성능 메트릭 저장소
- 제조 데이터 메트릭 저장소
- OLAP
- etc.
“실시간으로 데이터를 만지고 조회할 수 있는게 필요해!” 라면 다 적용 가능 하다는 내용인 것 같습니다. IoT같이 작은 데이터가 실시간으로 무수히 쌓이는 환경이라면 최적이라는 생각입니다.
Druid 특징
- 열 저장 형식(Columar DB)
- 열 조회 쿼리 속도가 크게 향상됩니다.
- 확장 가능한 분산 시스템
- Druid는 수십애에서 수백대까지 클러스터링 할 수 있습니다.
- 요건에 따라서 클러스터 노드 개수를 조정하면 됩니다.
- 대규모 병렬 처리
- 실시간 또는 일괄 수집
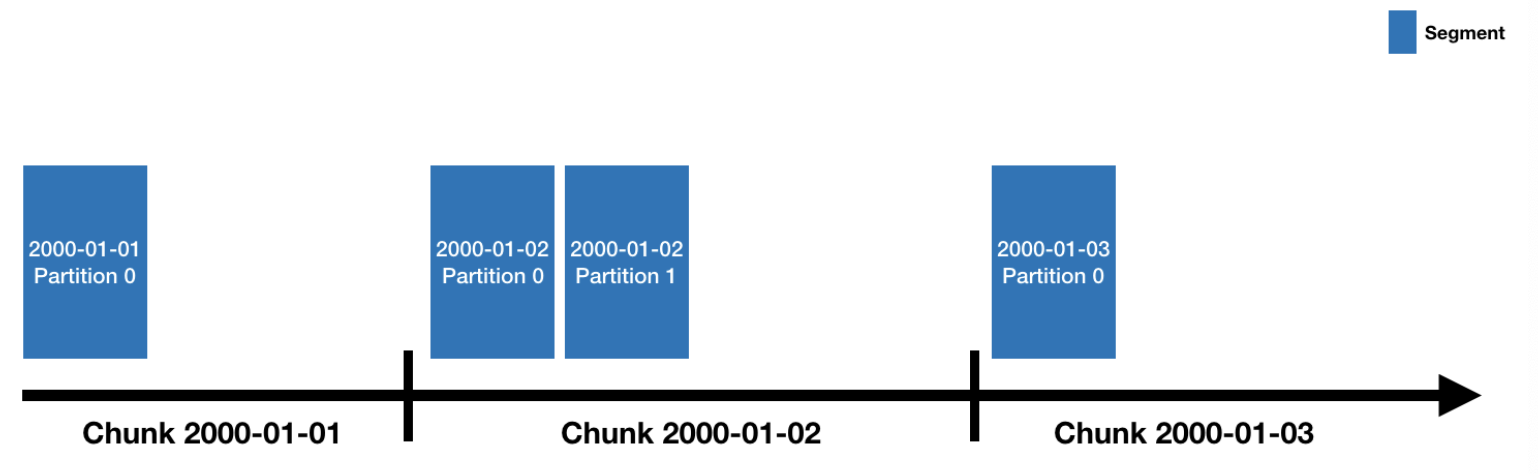
- Batch Ingestion(일괄... read more